


m浏览器官方手机版是一款清爽简洁的浏览器,无弹窗广告,功能便捷实用。它开放所有可扩展功能,允许用户根据个人喜好添加功能,打造专属的手机浏览器体验。软件功能丰富,支持视频播放、手势按钮、电视投屏、油猴脚本、广告拦截、书签同步等多种功能,为用户提供高效、便捷的浏览体验。
除了基础功能,m浏览器官方手机版还提供超级聚合搜索、DLNA电视投屏、审查元素、多内核浏览器切换、m3u8视频下载等特色功能,满足用户多样化的需求,提供专属的浏览体验。
另外m浏览器官方手机版对搜索功能进行了优化,打破传统搜索设计,采用多页面独立进程设计,确保搜索过程中数据不会错乱。多引擎框架不仅可自由集成各种网页数据,还能编写爬虫脚本深入挖掘和采集数据,轻松构建用户专属的数据库。
软件特色
1. 超级聚合搜索:多引擎、多爬虫,轻松自定义,极客必备功能。
2. 轻站小程序功能:直接在APP中,零基础即可开发。
3. 支持m3u8视频下载。
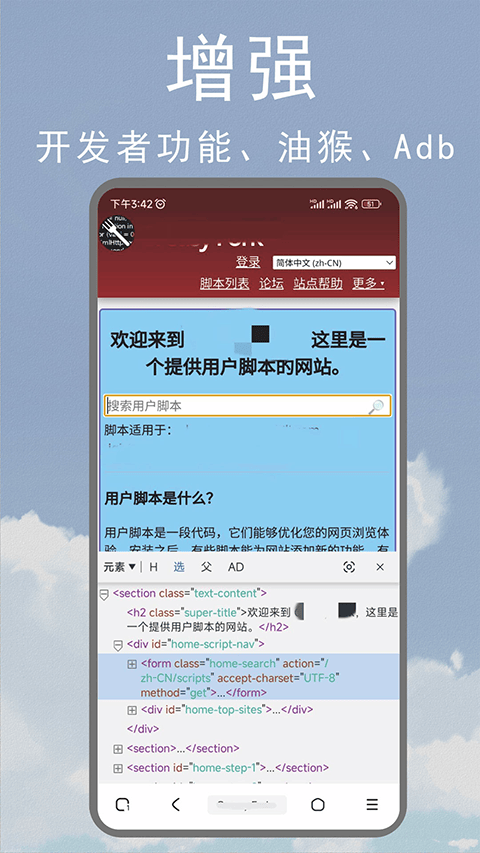
4. 支持审查元素功能,可随意修改网页内容。
5. 支持悬浮播放器 + 长按倍速功能。
6. 支持DLNA电视投屏功能。
7. 支持长按快速搜索,选中文字翻译、全局翻译。
8. 支持强大的ADB广告过滤插件。
9. 支持兼容油猴脚本功能。
10. 支持将第三方下载器(如IDM、ADM)设为默认浏览器。
11. 支持多内核浏览器切换。
12. 创新的隐藏手势操作,大屏时代,单手依然操作自如。
m浏览器轻站怎么使用
首先我们要了解轻站并非网站,而是一个简化版的小程序框架,其视图依赖安卓底层渲染,并非基于WebView(浏览框)。所以轻站与网站并无直接关系。
目前轻站的设计更适合后端开发者进行API调试工作。在未来的设计中,轻站将努力向原型设计方向迈进,以便产品或原型工作者在交付给客户端开发工程师之前确定原型的交互功能,减少因UI或参数改动导致的客户端代码重构频率。
作为一款极客APP,轻站框架也可以实现数据整合的目的,达到高效的数据预览效果。但请勿利用此特点进行非法操作!为了达到小团队交流的目的,所编写的轻站功能允许以扩展方式导出使用。为防止利用可输出特点进行非法买卖,软件不提供加密功能也无法做到加密(口令导出是经过压缩才会看到的都是一些乱码,实际并无加密),还请理解!
轻站自身不提供任何数据内容,也不做任何的内容检验及限制,所以使用其功能时,需要您承担所有风险,否则请勿使用该功能。
1. 创建一个新轻站或编辑已有引擎

2. 轻站框架组成
轻站由属性、模块、接口、常量、资源五个板块组成,其中以模块为主。
属性:轻站的信息。
模块:即页面,一个页面可以仅包含一个模块,也可以由多个模块嵌套而成。例如一个普通的列表只需使用一个列表模块即可;如果想在列表顶部嵌套一个幻灯片,就需要再去创建一个幻灯片模块,然后让列表模块嵌套进去。如果想要嵌套更多模块以使界面更丰富,就需要用到面板模块,面板模块可以同时嵌套N个不同类型的模块,达到不同的视觉效果。
接口:软件打开轻站的一个入口,首页就是在轻站列表中点开后默认开启的页面,搜索即搜索该轻站时展示的页面。
常量:固定的一个值,在模块运行时以获取变量的方式进行获取。
资源:存放本地资源,如JS文件、图片文件等,供模块调用,但暂未开放,暂不做介绍。
3. 模块详解
理论不如实践,以幻灯片模块为例,如图:若未搞过轻站的小同学请务必创建一个新的窗口来创建一个轻站完成以下图中操作。跟着操作一篇,基本上轻站也就会写啦!
数据源值:
百度##baidu.com##http://nr19.cn/p/baidu.jpg
搜狗##sogou.com##http://nr19.cn/p/sogou.jpg
谷歌##google.com##http://nr19.cn/p/sogou.jpg
视图数据值:(长按检索工具可一键导入)
表项=.fg()
标题=.tz(##)
地址=.ty(##)。tz(##)
图片=.ty2(##)
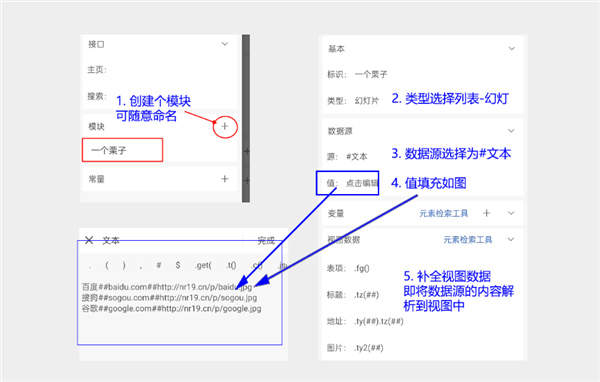
完成上述步骤,一个页面就做好啦,系部系很简单。

数据源就是视图的源内容,可以利用 #爬虫 去获取网络或本地的文本内容,如API、网页等,也可以像上面例子一样直接放 #文本 去放一个固定的文本内容。
先看一下轻站的运行流程图:
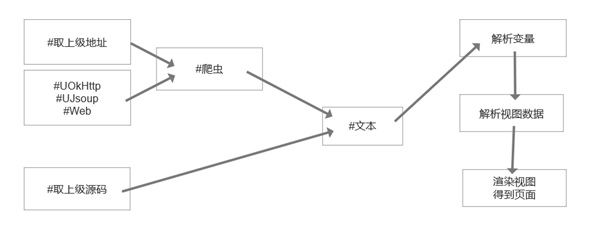
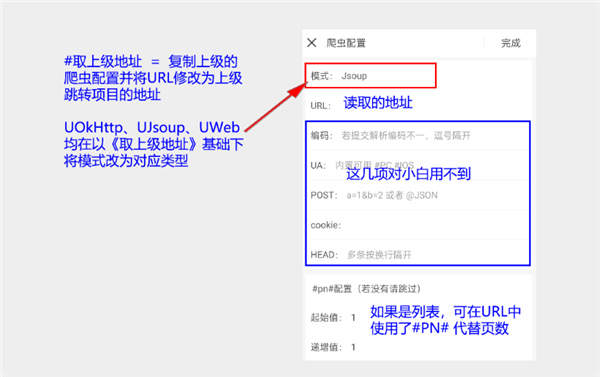
如上图所示不管数据源操作的是什么类型,最终目的都是获取一个文本,最后交由页面渲染器进行解析并将界面渲染出来。对了数据源中的 #爬虫 实际上和爬虫并无多大的关系,但也有一定的关系。爬虫的配置图解:
解析器使用E2表达式(为了写本软件而原创的一个新功能),详细的解析函数可查看文章:E2表达式函数大全。按照以上的运行流程图,会先解析“变量”数据,实际上视图数据中的就是变量,不过是自定义的变量优先解析,在E2里是允许取变量的,模块里变量的出现是为了防止在视图数据一行E2无法做到详细的解析,一般情况下也不需要自定义变量。
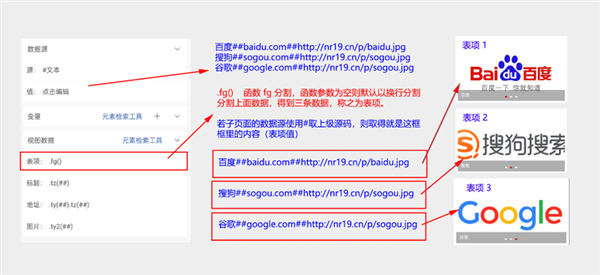
到这里轻站功能的开发已经介绍完毕,相信你也已经掌握了轻站的原理,是不是特别的简单。
使用教程
1. 打开在本站下载的M浏览器,第一步,打开软件首页,点击轻站按钮。
2. 第二步,点击右上角的+号。

3. 第三步,点击源仓库。

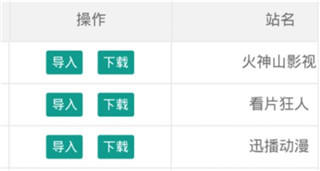
4. 进入下面这个界面之后,大家就可以挑选自己需要的源啦,找到需要的,点击导入即可哦。
软件功能
1. 超级聚合搜索,多引擎、多爬虫,轻松自定义,极客必备功能。
2. 直接在APP中,零基础就能开发的轻站小程序功能。
3. 支持m3u8视频下载。
4. 支持审查元素功能,可随意修改网页内容。
5. 支持悬浮播放器 + 长按倍速功能。
6. 支持DLNA电视投屏功能。
7. 支持长按快速搜索,选中文字翻译、全局翻译。
8. 支持强大的ADB广告过滤插件。
9. 支持兼容油猴脚本功能。
10. 支持将第三方下载器(如IDM、ADM)设为默认浏览器。
11. 支持多内核浏览器切换。
12. 创新的隐藏手势操作,大屏时代,单手依然操作自如。
E2表达式函数大全
E2表达式用于M浏览器的爬虫功能上,如果你要自己去尝试写脚本就需要了解一下。
E2 表达式
用于处理文本的表达式,比如获取"文本"前的几个字,可以使用 .tz(文本) 获取到 "用于处理" 四个字。 E2函数名使用中文拼音首字命名,对不懂开发的人群也能轻松操作。
E2 还能进行数组操作,在M浏览器里轻站或虫子获取列表的函数就需要获取数组。为了更容易了解并使用函数,一般处理文本的函数均以 t 开头,比如取文本左边的 tz , t = 文本,z 是左的拼音头,然后就能知道取文本右边函数为 ty 了。 处理数组的函数 以 i 开头,如 .ij(aaa) ,j = 加, 往数据中加入一行数组,值为 aaa 。
以下函数仅支持 2.3.5 及以上版本支持
文本操作类:
.tz() .ty() 取文本左、右数据。
.tz2() .ty2() 从后读取判断值文本并取判断值左、右(前、后)数据。 若内容为 abbacc 时使用 .ty(a) 取得值为 bbacc , 使用 .ty2(a) 取得值 为 cc 。
.t() 删除HTML标识,无需提供参数,如内容为
a
b
时去除html代码获取正文, 直接使用 .t() 即可,最终得到 ab
.tj() 添加内容,如已有 ab 获取 abcd : .tj(cd)
.tzc() 参数为数字,如 tzc(5) 如果当前操作值字数大于 5 就取前5个字,少于则取全部。所以这里 zc 记最长。若操作值为 ABCDE 使用 .tzc(3) 得到 AB
.tsk() 无参数,去首尾空,qswk 再加上 t 太长了不好记,就首空,意思就去首尾空,就是去掉操作首尾的空格字符
.th() 替换,参数为 欲被替换文本##替换文本。如内容为 ABC 时 需将 B 改成 2 ,可以使用 .th(B##2) 。 欲需将其置空不要,可以直接使用 .th(B) ,将得到 AB 。 同时 th 中欲被替换文本是支持正则表达式的,如果要替换的内容和正则通配符冲突的话,就需要写转义了。 比如相对复杂的内容 111ADGDGS333 将中间的英文字替换为333,可用 .th([A-Z]+##333) 。 如果你并不知道哪些是正则匹配符,建议使用 .th2() 唯一不同的是 th2 中欲被替换文本是不支持正则匹配的。
.tx() x 意思是 新,新的概念在下面的数组里也有相应的函数。 M浏览器扩展使用E2时都是要先定义源内容的,比如数据源爬虫就是读取到的网络内容,文本就是定义的文本。 这里假设源内容是 xByyEzz , 需要获取 E 后面的值和 B 前面的值(其中内容 x y z 会动态变化),注意是E后面+B前面。 新的概念就是存储之前操作的值不变让后面操作的函数处理的是源内容。理解这句话应该知道怎么做了,分三步走,获取 E 的后面值 ty2(E) -> 存储并将当前操作内容定义为源内容 tx() -> 获取 B 前面值 .tz(B)。
快速捋一篇 源内容 xByyEzz 在使用 E2 时会自动将其转为操作值,跟着使用 ty2(E) ,取E后面就是将操作值置为 zz , 接着使用 .tx() 存储操作值并将操作值设为源文本 xByyEzz , 跟着 tz(B) 得到 x 。后面没有函数了,就将前面存储的值和操作值输出,最终得到 xyyzz 。
加解密操作:
.en() 加密 .dn() 解密
.en(base64) / .dn(base64) ----- base64 加密 及 解密
.en(md5) --- 获取MD5
.en/dn(utf-8/gbk等编码值) --- URL编码及解码
aes des 3des 加解密 注意参数之间以小写逗号分隔 输出类型仅两种 hex(16进制) 及 base64
.en/dn (aes,模式,密码,编码,输出类型,偏移量)
数组操作类:
.i(正数) 获取数组中第一个内容,从0开始,如获取第一个值 就 .i(0) ,第三个值 .i(2) 以此类推
.i(负数) 从数组尾部开始寻找,-1 即,数组倒数第一个值。 -2 数组倒数第二值,以此类推
.i(数,数) 取数组范围,理解了正数负数的用法这里的数可以自由填正数也可以负数,怎么好判断怎么来, 如有数组 [ab,ac,ad,ae] ,获取 ac,ad,ae ,即排除第一个: .i(1,-1) ,排除最后一个: .i(0,-2)
.ij(添加的文本) 将"添加的文本" 加入到数组中,比如数组已经有 [aa,bb,cc] 操作之后就等于 [aa,bb,cc,添加的文本]
.ix() 存储数组,接着和 tx 类似,将操作值改为原文本。 注意数组操作时接着操作其它函数
.it(分割符) E2里,i 表示数组,t 表示文本。将数组合并为文本且中间以参数分隔符作填充,若不填入参数则无分隔符
正则表达式
.z() 参数中若含括号必须添加转义给E2识别,若正则表达式中括号比较多在E2里看起来比较费眼,可在参数前后添加两个@标识内容为参数。 比如正则为 (a\(b\)c)|(x\(y\)z) ,就是匹配 a(b)c 或 x(y) z, 在E2里必须给括号再添加一个转义符 \ ,即 .z(\(a\\(b\\)c\)|\(x\\(y\\)z\)) 这样就看起来很乱,那如果在参数两则加双@ 就可以写成 .z(@@(a\(b\)c)|(x\(y\)z)@@) 看起来相对会比较和谐。
.z2() 匹配子表达式,同上一些编写,子表达式即为 正则中()里面的值,匹配后可以使用 .i() 获取指定括号内容。 点这里查看正则语法 : https://www.runoob.com/regexp/regexp-syntax.html
CSS选择器
.css(选择器语法) 返回匹配得到的数组,匹配语法说明:https://blog.csdn.net/weixin_34375233/article/details/89656172
.a(属性名) 返回属性值,如 a 标签的 href 属性(跳转地址): .a(href) 。 img标签的图片属性src(图片地址):。a(src)
XML解析器
.xml(标签名) 和 .css 用法一致
JSON解析器
.json(参数名) 不管是普通对象还是数组对象,都这个命令。数组对象返回数组、文本对象返回文本(也可以将其视为只有一个子项的数组)。
更新日志
v3.2.4.0706版本
更新说明:
修复通用设置项视频长按倍速设置无效。
修复部分机型扫码报错。
游戏图片

热门推荐











游戏攻略
新游top榜
更多游戏




 关注公众号
关注公众号
 加入粉丝群
加入粉丝群